1956年,几个计算机科学家相聚在达特茅斯会议(Dartmouth Conferences),提出了“人工智能”的概念。其后,人工智能就一直萦绕于人们的脑海之中,并在科研实验室中慢慢孵化。之后的几十年,人工智能一直在两极反转,或被称作人类文明耀眼未来的预言;或者被当成技术疯子的狂想扔到垃圾堆里。坦白说,直到2012年之前,这两种声音还在同时存在。
过去几年,尤其是2015年以来,人工智能开始大爆发。很大一部分是由于GPU的广泛应用,使得并行计算变得更快、更便宜、更有效。当然,无限拓展的存储能力和骤然爆发的数据洪流(大数据)的组合拳,也使得图像数据、文本数据、交易数据、映射数据全面海量爆发
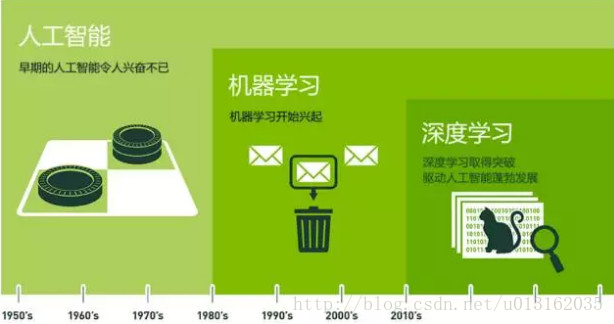
人工智能(Artificial Intelligence)——为机器赋予人的智能
早在1956年夏天那次会议,人工智能的先驱们就梦想着用当时刚刚出现的计算机来构造复杂的、拥有与人类智慧同样本质特性的机器。这就是我们现在所说的“强人工智能”(General AI)。这个无所不能的机器,它有着我们所有的感知(甚至比人更多),我们所有的理性,可以像我们一样思考。
人们在电影里也总是看到这样的机器:友好的,像星球大战中的C-3PO;邪恶的,如终结者。强人工智能现在还只存在于电影和科幻小说中,原因不难理解,我们还没法实现它们,至少目前还不行。
我们目前能实现的,一般被称为“弱人工智能”(Narrow AI)。弱人工智能是能够与人一样,甚至比人更好地执行特定任务的技术。例如,Pinterest上的图像分类;或者Facebook的人脸识别。
这些是弱人工智能在实践中的例子。这些技术实现的是人类智能的一些具体的局部。但它们是如何实现的?这种智能是从何而来?这就带我们来到同心圆的里面一层,机器学习。
机器学习—— 一种实现人工智能的方法
机器学习最基本的做法,是使用算法来解析数据、从中学习,然后对真实世界中的事件做出决策和预测。与传统的为解决特定任务、硬编码的软件程序不同,机器学习是用大量的数据来“训练”,通过各种算法从数据中学习如何完成任务。
机器学习直接来源于早期的人工智能领域。传统算法包括决策树学习、推导逻辑规划、聚类、强化学习和贝叶斯网络等等。众所周知,我们还没有实现强人工智能。早期机器学习方法甚至都无法实现弱人工智能。
机器学习最成功的应用领域是计算机视觉,虽然也还是需要大量的手工编码来完成工作。人们需要手工编写分类器、边缘检测滤波器,以便让程序能识别物体从哪里开始,到哪里结束;写形状检测程序来判断检测对象是不是有八条边;写分类器来识别字母“ST-O-P”。使用以上这些手工编写的分类器,人们总算可以开发算法来感知图像,判断图像是不是一个停止标志牌。
这个结果还算不错,但并不是那种能让人为之一振的成功。特别是遇到云雾天,标志牌变得不是那么清晰可见,又或者被树遮挡一部分,算法就难以成功了。这就是为什么前一段时间,计算机视觉的性能一直无法接近到人的能力。它太僵化,太容易受环境条件的干扰。
深度学习——一种实现机器学习的技术
人工神经网络(Artificial Neural Networks)是早期机器学习中的一个重要的算法,历经数十年风风雨雨。神经网络的原理是受我们大脑的生理结构——互相交叉相连的神经元启发。但与大脑中一个神经元可以连接一定距离内的任意神经元不同,人工神经网络具有离散的层、连接和数据传播的方向。
例如,我们可以把一幅图像切分成图像块,输入到神经网络的第一层。在第一层的每一个神经元都把数据传递到第二层。第二层的神经元也是完成类似的工作,把数据传递到第三层,以此类推,直到最后一层,然后生成结果。
每一个神经元都为它的输入分配权重,这个权重的正确与否与其执行的任务直接相关。最终的输出由这些权重加总来决定。
我们仍以停止(Stop)标志牌为例。将一个停止标志牌图像的所有元素都打碎,然后用神经元进行“检查”:八边形的外形、救火车般的红颜色、鲜明突出的字母、交通标志的典型尺寸和静止不动运动特性等等。神经网络的任务就是给出结论,它到底是不是一个停止标志牌。神经网络会根据所有权重,给出一个经过深思熟虑的猜测——“概率向量”。
这个例子里,系统可能会给出这样的结果:86%可能是一个停止标志牌;7%的可能是一个限速标志牌;5%的可能是一个风筝挂在树上等等。然后网络结构告知神经网络,它的结论是否正确。
即使是这个例子,也算是比较超前了。直到前不久,神经网络也还是为人工智能圈所淡忘。其实在人工智能出现的早期,神经网络就已经存在了,但神经网络对于“智能”的贡献微乎其微。主要问题是,即使是最基本的神经网络,也需要大量的运算。神经网络算法的运算需求难以得到满足。
不过,还是有一些虔诚的研究团队,以多伦多大学的Geoffrey Hinton为代表,坚持研究,实现了以超算为目标的并行算法的运行与概念证明。但也直到GPU得到广泛应用,这些努力才见到成效。
我们回过头来看这个停止标志识别的例子。神经网络是调制、训练出来的,时不时还是很容易出错的。它最需要的,就是训练。需要成百上千甚至几百万张图像来训练,直到神经元的输入的权值都被调制得十分精确,无论是否有雾,晴天还是雨天,每次都能得到正确的结果。
只有这个时候,我们才可以说神经网络成功地自学习到一个停止标志的样子;或者在Facebook的应用里,神经网络自学习了你妈妈的脸;又或者是2012年吴恩达(Andrew Ng)教授在Google实现了神经网络学习到猫的样子等等。
吴教授的突破在于,把这些神经网络从基础上显著地增大了。层数非常多,神经元也非常多,然后给系统输入海量的数据,来训练网络。在吴教授这里,数据是一千万YouTube视频中的图像。吴教授为深度学习(deep learning)加入了“深度”(deep)。这里的“深度”就是说神经网络中众多的层。
现在,经过深度学习训练的图像识别,在一些场景中甚至可以比人做得更好:从识别猫,到辨别血液中癌症的早期成分,到识别核磁共振成像中的肿瘤。Google的AlphaGo先是学会了如何下围棋,然后与它自己下棋训练。它训练自己神经网络的方法,就是不断地与自己下棋,反复地下,永不停歇。
深度学习,给人工智能以璀璨的未来
深度学习使得机器学习能够实现众多的应用,并拓展了人工智能的领域范围。深度学习摧枯拉朽般地实现了各种任务,使得似乎所有的机器辅助功能都变为可能。无人驾驶汽车,预防性医疗保健,甚至是更好的电影推荐,都近在眼前,或者即将实现。
人工智能就在现在,就在明天。有了深度学习,人工智能甚至可以达到我们畅想的科幻小说一般。你的C-3PO我拿走了,你有你的终结者就好了。
【注】机器视觉(Machine Vision, MV) & 计算机视觉(Computer Vision, CV)
从学科分类上, 二者都被认为是 Artificial Intelligence 下属科目。
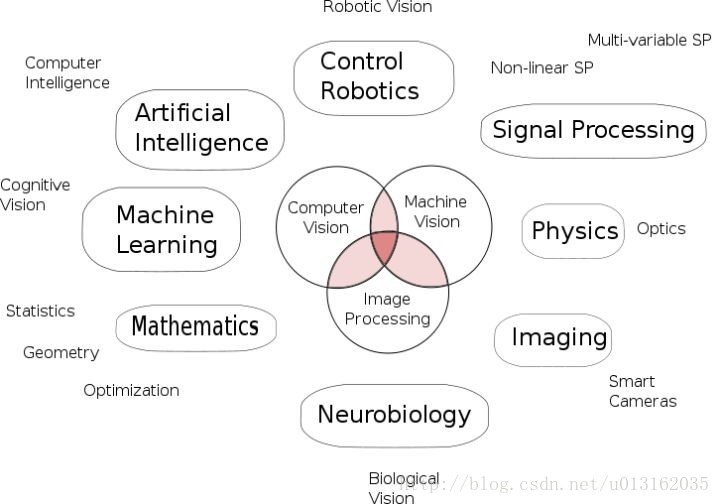
计算机视觉是采用图像处理、模式识别、人工智能技术相结合的手段,着重于一幅或多幅图像的计算机分析。图像可以由单个或多个传感器获取,也可以在单个传感器在不同时刻获取的图像序列,分析是对目标物体的识别,确定目标物体的位置和姿态,对三维景物进行符号描述和解释。在计算机视觉中,经常使用几何模型、复杂的知识表达,采用基于模型的匹配和搜索技术,搜索的策略常使用自底向上、自顶向下、分层和启发式控制策略。
机器视觉则偏重于计算机技术工程化,你问哪个够自动获取和分析特定的图像和场景,以控制相应的行为。具体的说,计算机视觉为机器视觉提供图像和精武分析的理论及算法基础,机器视觉为计算机视觉的实现提供了传感器模型、系统构造和实现手段。因此可以认为,一个机器视觉系统就是一个自动获取一幅或多幅目标物体图像,对所获取图像的各种特征量进行处理、分析和测量,并对测量结果做出定性的分析和定量解释,从而得到有关目标物体的某种认识并做出下相应决策的系统。机器视觉系统的功能包括:物体定位、特征检测、缺陷判断、目标识别、计数和运动跟踪。